Building with AI as a developer sounds like a solved problem until you ship something that breaks in a way no test caught. The tools are good. The gap is in how most developers are using them, which is to generate code they don’t fully understand inside systems where they will eventually need to. This hub documents the full development workflow with AI, from local inference to production pipelines, written for engineers who have already moved past the “what is an LLM” stage and need the practitioner layer the generic guides skip.
EAI’s AI Development and Coding cluster covers every part of this stack. This page is the index.
Where Most Developers Go Wrong With AI Coding
The first mistake is treating AI coding tools as a faster version of copy-pasting Stack Overflow answers. The second is treating them as a replacement for understanding the system. Both produce the same failure mode: code that looks right, passes shallow tests, and breaks under conditions the AI was never shown.
The actual problem with building with AI as a developer is not that the tools are bad. They are genuinely useful for boilerplate, debugging, and rapid scaffolding. The problem is that most developers apply AI at the code-generation layer without applying discipline at the architecture, validation, and production-verification layers. The code gets written faster. The understanding does not keep pace. That gap is where production incidents live.
Vibe coding is the name that has stuck to the pattern where you describe what you want, accept what the model generates, and keep prompting until it seems to work. Vibe coding is fine until something breaks, which is a statement about timing, not condemnation. The issue is that “seems to work” and “works under all production conditions” are two different things, and AI tools have no way to know the difference unless you build a system that forces them to.
The Stack Layer by Layer
Building with AI as a developer in 2026 means making deliberate choices about where AI runs, not just which tools to use. The two fundamental decisions are cloud versus local, and generation versus orchestration.
Cloud tools (Claude, GPT-based editors, Copilot, Cursor) are fastest for code generation, have the largest context windows, and integrate cleanly with existing IDEs. Their constraints are session limits, API costs, and the fact that everything you send them leaves your machine. For most commercial work this is acceptable. For anything involving proprietary logic, client data, or cost-sensitive pipelines, it deserves a second look.
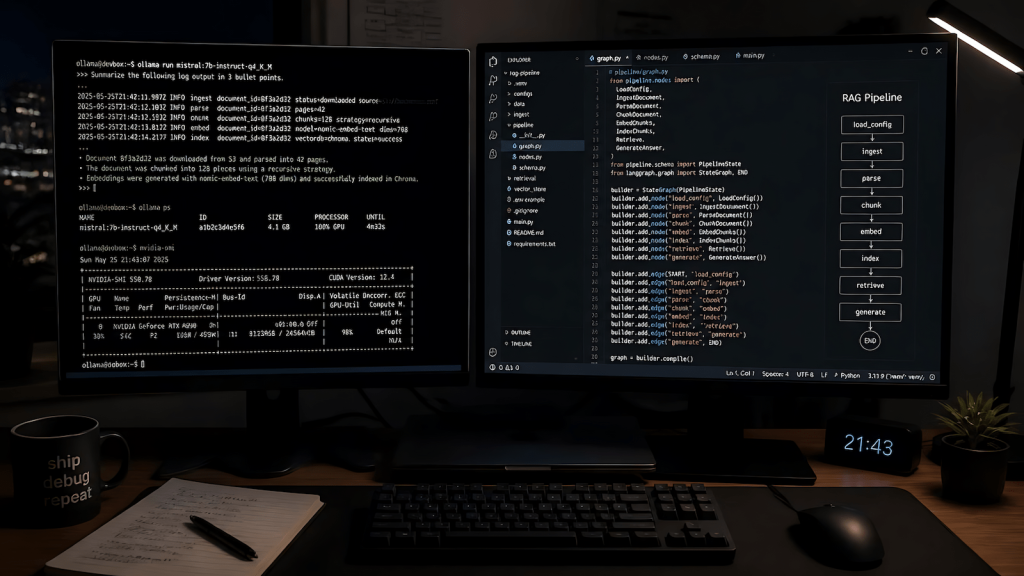
Local inference (Ollama, llama.cpp, LM Studio) runs on your own hardware, has no session limits, costs nothing per token, and keeps your code on your machine. The tradeoff is VRAM constraints and the quality ceiling that comes with running smaller models. A GTX 1660 6GB runs Mistral 7B well enough for code review, formatting, and lightweight generation tasks, but will not match GPT-4-class output for complex reasoning. The practical move is a hybrid stack: use local models for tasks a free local model can handle and route to cloud only when the task actually requires it.
Context engineering is the third variable most developers ignore. The quality of AI-generated code correlates more strongly with what the model sees before it answers than with which model you use. A well-structured prompt contract with clear task definition, scope, output format, and failure handling will outperform a vague request sent to a more capable model. Prompt contracts handle the edge cases that conversational prompts miss. Context engineering is the discipline that makes this systematic.
Writing Code Yourself vs. Letting the Model Do It
This is not a philosophical question. It is an architectural one. Some parts of a codebase benefit from AI generation. Others do not, and generating them anyway creates a maintenance and comprehension debt that shows up later.
Write the code yourself when: you are defining the core architecture, you are implementing logic that will be critical to debug under production conditions, or you are working on a system where you need to reason about edge cases that the model cannot have been trained on. Boilerplate, repetitive scaffolding, test case generation, documentation, and format conversion are all legitimate AI tasks where generation speed outweighs comprehension cost.
How developers actually use AI in practice differs significantly from how it gets described in blog posts. The real workflow is not “AI writes everything.” It is a layered division of labor where the developer owns the architecture and the AI handles the execution of well-defined sub-tasks.
When AI-Generated Code Passes Tests and Still Breaks in Production
AI-generated code that passes tests can still break in production, and this is the failure mode that catches developers who applied discipline at the generation layer but not the verification layer. The test suite covers the cases the developer wrote tests for. Production encounters the cases nobody anticipated.
The pattern is consistent: AI generates code that satisfies the stated requirements and passes the tests that were written for those requirements. The deployment exposes a condition the model was never shown and the tests never covered. This is not a model failure. It is a process failure where the verification layer was not built to catch what AI generation cannot guarantee.
The mitigation is not to stop using AI for code generation. It is to build the verification layer explicitly, treat every AI-generated function as code that needs the same review and test coverage as code from a junior developer you supervise, and never let “it passed the CI” serve as the final quality gate.
Pipelines, Agents, and Multi-Model Systems
Building with AI as a developer increasingly means building systems where AI is a component, not just a tool you query. Structuring AI pipelines like an engineer means explicit input contracts, output validation, and failure state handling, not just the happy path the tutorial shows.
Multi-agent local AI systems add orchestration complexity on top of inference complexity. When multiple models are handling different stages of a task, the failure modes multiply. A model that misclassifies input at stage one produces garbage at stage three with no error thrown. Designing these systems with QA thinking from the start (what does a bad output look like, how does the system detect it, what is the recovery path) is what separates a working pipeline from one that produces plausible-looking failures.
Autonomous AI publishing pipelines are a real example of what breaks when this discipline is skipped. The pipeline ran. The problems were at every integration point where the system had to hand off between components, validate external state, or handle an output format it had never encountered in testing.
MCP (Model Context Protocol) changes the tool-use layer for local AI systems. Setting up a local MCP server with Ollama is now a practical option for developers who want persistent tool access without wiring every capability through n8n nodes. The architecture is simpler at the edges and more maintainable than custom integrations.
The QA Layer Nobody Talks About
AI is reshaping software testing, but the developers most exposed to AI-generated code failures are the ones treating QA as a downstream problem someone else handles. In a vibe team software engineering workflow, the QA layer is built into the development cycle, not added at the end.
Teaching LLMs with proper data evaluation matters at the pipeline design stage. Models that produce structured output need explicit validation before that output flows downstream. This is not optional. It is the difference between a pipeline that catches its own errors and one that propagates them silently.
Fragmentation as a design principle applies here directly. Systems that break a complex AI task into discrete, validatable steps are more reliable and easier to debug than monolithic pipelines that try to do everything in a single model call. The fragmentation point is where you insert your validation gate.
What Building With AI as a Developer Actually Requires
The developers who get the most out of AI coding tools are not the ones using the newest tools. They are the ones who have built the surrounding system that makes AI output trustworthy: clear task boundaries, explicit validation, production monitoring, and genuine understanding of what the model cannot know.
AI IDEs are changing what it means to be a developer, but the change is not that understanding the system matters less. The change is that developers who understand their systems can move significantly faster using AI for execution while retaining the judgment that keeps production stable. Developers who skip the understanding in favor of generation speed are accumulating a debt that eventually comes due.
Context engineering is the foundational skill that improves everything else. How you structure what the model sees determines the quality of what it produces, regardless of which model you use. Mastering this is a higher-leverage investment than switching tools.
Building with AI as a developer is not a shortcut. It is a more powerful version of the same engineering discipline that made good software before AI coding tools existed. The discipline does not disappear. It moves to a different layer.
Where to Go From Here
This is the hub for EAI’s AI Development and Coding cluster. Start with the post that matches where you are:
If you’re deciding when to write code yourself: When to Write Code Yourself and When to Let the Model Do It
If you’re running a local AI stack: Running AI Locally: What the Setup Actually Looks Like on Consumer Hardware and How to Set Up a Local MCP Server with Ollama
If your AI-generated code is breaking in production: Why AI-Generated Code Passes Tests But Breaks in Production
If you’re building pipelines: Structuring AI Pipelines Like an Engineer and What Actually Breaks When You Run an Autonomous AI Publishing Pipeline
If you’re building multi-agent systems: How I Architected a Multi-Agent Local AI System Using PM and QA Thinking
If you’re thinking about context and prompting: Context Engineering for LLMs and Prompt Contracts: How to Write AI Instructions That Don’t Break Under Edge Cases