The mental model that finally made my multi-agent local AI system architecture click wasn’t from an AI paper or an agent framework tutorial. It was from fifteen years of running QA pipelines and managing projects where requirements changed mid-sprint and the system had to absorb the change without breaking. The moment I stopped thinking about Alfred, my local AI content operation, as an “AI system” and started thinking about it as a project with roles, handoffs, and quality gates, everything became easier to reason about and easier to build.
This is a documentation of that architecture: what it does, how it’s structured, and specifically which mental models from PM and QA work made the design decisions obvious rather than experimental.
The insight nobody tells you: this is systems design, not AI research
Most multi-agent AI content assumes you’re coming from a machine learning background. The literature talks about agent frameworks, model routing, embedding strategies, and context window optimization. That’s real and useful if you’re doing ML research. It’s also a significant misdirection if you’re a technical generalist who wants to build something that works reliably on a local machine without a PhD.
What a multi-agent system actually is, stripped of the ML framing, is a workflow with specialized roles and defined handoffs. One component researches. One writes. One edits. One handles distribution. Each component has a specific input, a specific output, and a specific failure mode. If you’ve ever designed a sprint where different team members own different stages of delivery, you’ve already designed a multi-agent architecture. You just didn’t call it that.
This reframe isn’t a simplification. It’s the accurate description. The complexity in multi-agent systems doesn’t live in the AI parts. It lives in the orchestration, the state management, the error handling, and the quality gates between stages. Those are systems engineering problems, and they respond to systems engineering thinking.
What the system actually does: four casts, five agents
Alfred is organized around four casts, named subsystems with distinct responsibilities, and five agents that operate across them.
Scribecast handles WordPress draft creation. It takes a finalized brief, runs it through the Writer and Editor agents, and outputs a structured draft logged to Notion. EchoCast handles syndication, taking the published canonical post and distributing file-output versions across platforms on a staggered schedule. FireCast monitors trend signals via RSS, selects the strongest niche-relevant signal, and generates platform-native social copy. ReelCast is the video pipeline, scripting and assembling short-form video content from local free tools without paid services.
The five agents, Researcher, Writer, Editor, Affiliate, and Vibe Coder, aren’t tied to one cast. They’re roles that get invoked by whichever cast needs them. Researcher feeds both Scribecast and FireCast. Writer and Editor operate inside Scribecast. Affiliate runs during draft creation when a post has commercial intent. Vibe Coder handles the code-adjacent tasks that come up in pipeline maintenance.
What makes this a multi-agent local AI system architecture rather than a collection of scripts is the deliberate separation of concerns. Each agent has a bounded job. No agent makes decisions outside its scope. The orchestration layer, n8n plus Ollama, manages the flow between them.
Where PM thinking built the architecture
Project management thinking contributed three things to this architecture: role definition, handoff design, and the concept of a brief as a source of truth.
Role definition first. In any functional project team, you don’t have one person doing research, writing, editing, and distribution simultaneously. You define roles because context-switching is expensive and specialization produces better output. The same logic applies to agents. A model told to research, write, and optimize for SEO in the same prompt produces mediocre output across all three. A model told to do one thing, given a system prompt that makes it very good at that one thing, produces something defensible. The agent specialization in Alfred is just good PM resourcing applied to a local LLM stack.
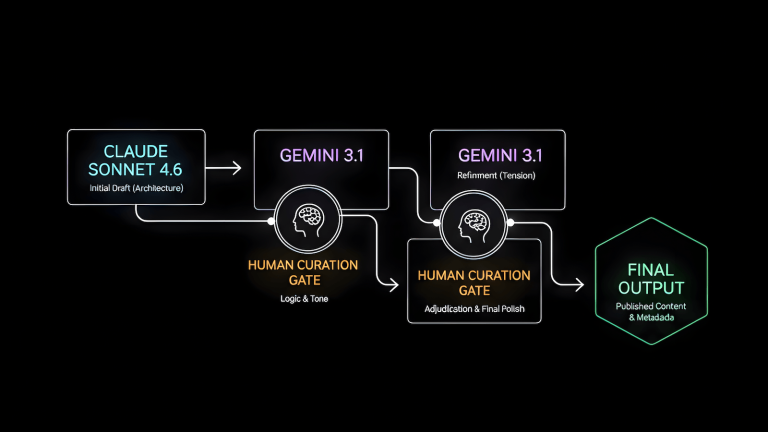
Handoff design is the second contribution. In PM, the failure mode that kills projects isn’t usually the work itself. It’s the gap between stages where information gets lost, misinterpreted, or assumed rather than communicated. In Alfred, every handoff is a structured artifact: the brief goes from the brainstorm layer to Scribecast as a formatted document with locked requirements. The draft goes from Scribecast to EchoCast as a completed file with a Notion ticket attached. Nothing moves forward on an assumption. This is standard PM practice, and it’s what keeps the pipeline from accumulating drift over time.
The brief as source of truth is the third piece. In project management, you run work against requirements. In Alfred, the brief is the requirements document. It’s finalized before any writing happens, it doesn’t change during execution, and every output is evaluated against it. The brainstorm layer, a Discord channel where Researcher, SEO Master, Editor, and Marketer agents deliberate before anything gets written, exists specifically to harden the brief before it enters the production pipeline. No brief, no execution. This is sprint planning logic applied to AI content operations.
Where QA thinking kept it from collapsing
QA contributed three things: failure mode mapping, the concept of a quality gate, and the discipline of testing outputs before treating them as production-ready.
Failure mode mapping is the most underrated practice in AI pipeline design. Before any component of Alfred ran in production, I mapped the ways it could fail. What happens if Researcher returns a hallucinated source? What happens if Writer produces a draft that doesn’t match the brief? What happens if EchoCast’s Playwright script hits an anti-bot block mid-session? Each failure mode has a defined behavior: log it, flag it in Discord, stop the run, wait for human review. There’s no silent failure in Alfred. If something breaks, it surfaces. This is basic QA discipline — you don’t ship without knowing what the error states look like.
Quality gates are the second contribution. In QA, a gate is a checkpoint where output is evaluated before it moves to the next stage. Alfred has gates at every cast boundary. A brief doesn’t enter Scribecast until it’s been reviewed in the brainstorm channel. A draft doesn’t get syndicated by EchoCast until it’s been published and indexed as canonical. A trend signal doesn’t generate social copy until FireCast confirms it’s niche-relevant against the site’s topic cluster. These gates exist because AI output without review is a liability, and gates are cheaper than cleanup.
The third contribution is the most philosophical: QA thinking treats every output as potentially wrong until demonstrated otherwise. This is the opposite of the default behavior most people bring to AI tools, which is to treat model output as probably right unless it’s obviously broken. Running a multi-agent local AI system with QA instincts means reading every draft for drift from the brief, checking every syndicated output against the canonical, and verifying that FireCast’s strongest signal actually maps to the site’s content strategy before letting it generate copy. The system produces. Human judgment verifies. That’s the operating model.
Discord as workspace, Notion as record
The tool choices here are deliberate and worth explaining briefly, because they’re often the first thing people want to swap out.
Discord is the workspace because it’s a real-time channel-based interface that maps cleanly to the agent collaboration model. The brainstorm layer lives in a dedicated channel where agents post their analysis and a human makes the final call before the brief is locked. FireCast posts trend signals to a separate channel. Production status updates land in another. Discord isn’t being used as a chatbot host. It’s being used as an operations dashboard with natural language output from agents and human-readable state at a glance.
Notion is the record because every piece of work in Alfred traces back to a ticket. The brief is a Notion page. The draft completion is logged to that page. The syndication status is logged to that page. When something breaks, you go to Notion and see where the pipeline stopped. When you want to understand why a post performed a certain way, the brief and the editorial decisions are all on the same ticket. Notion isn’t a database for Alfred’s outputs. It’s the audit trail for Alfred’s decisions.
This combination, Discord for live orchestration and Notion for permanent record, is the same logic as a project management setup where Slack handles day-to-day communication and a ticket system holds the history. The tools aren’t novel. The application of them to a local AI system architecture is.
What this means if you’re not an ML engineer
If you have a PM or QA background and you’re looking at multi-agent AI systems and feeling like you need to learn a different discipline to build one, you don’t. The discipline you need is systems thinking, and you already have it. The AI components are the execution layer. The architecture, the roles, the handoffs, the gates, the records, is built with the same thinking you use to run a competent project or manage a QA pipeline.
What you do need to learn is the tooling specific to local AI: how Ollama serves models, how n8n handles workflow orchestration, how to write a system prompt that makes an agent specialized rather than generic. Those are learnable technical skills, not conceptual barriers. The conceptual work is understanding that multi-agent local AI system architecture is a workflow design problem first and an AI problem second. Once that clicks, the rest is implementation.