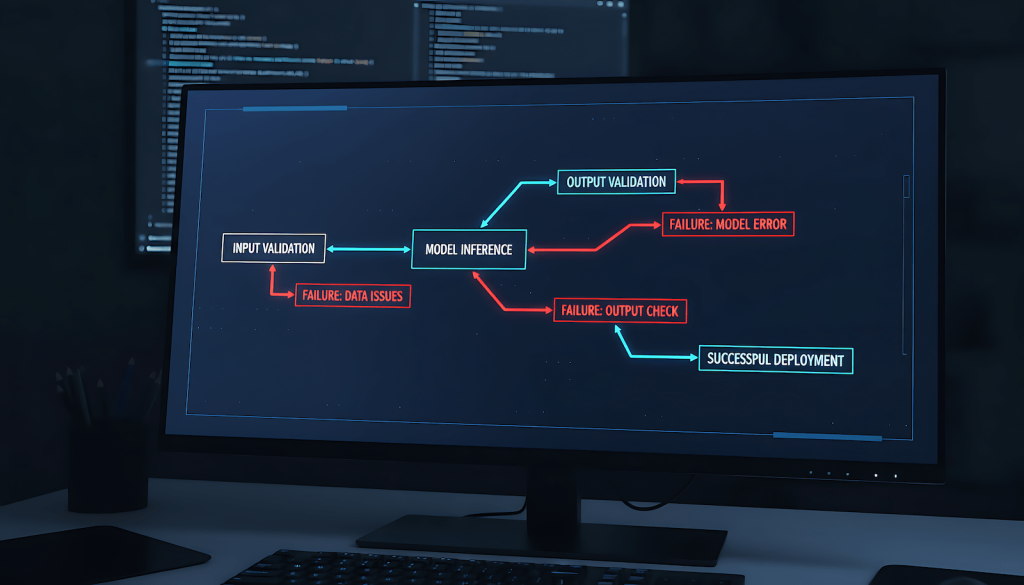
Most AI pipeline tutorials show you the happy path. Input goes in, model processes it, output comes out, everyone claps. What they skip is everything that happens when the input is malformed, the model returns garbage, the downstream system rejects the output format, or the whole thing silently fails without throwing an error. Structuring AI pipelines like an engineer means treating failure states as first-class design concerns, not edge cases to handle later.
The difference between a pipeline that works in a demo and one that runs reliably in production is almost entirely about how you define and handle the boundaries. Inputs need validation before they reach the model. Outputs need validation before they reach the next stage. Failure states need explicit handling at every step. This is not glamorous work, but it’s the work that determines whether your agentic AI workflow survives contact with real data.
Define Your Input Contract First
An AI pipeline without an explicit input contract is a pipeline that will fail in ways you can’t predict. The input contract specifies what the model expects: format, length, language, encoding, required fields, and acceptable ranges for any structured inputs. Before a single token reaches the model, every input should be validated against this contract. Inputs that don’t conform get rejected or sanitized not silently passed through.
Length validation matters more for LLM pipelines than most engineers expect because models have context windows, and inputs that exceed them either get truncated silently or throw errors depending on the framework. Neither is acceptable without explicit handling. Measure your actual input distribution early, set a hard limit below the context window ceiling, and decide explicitly what happens to inputs that exceed it — truncate with a strategy, chunk and process in sequence, or reject with an informative error. The context engineering approach to managing what goes into a model’s context window is directly relevant here.
Output Validation Is Not Optional
LLMs do not reliably return structured output just because you asked them to. A model prompted to return JSON will occasionally return JSON wrapped in markdown code fences, JSON with a preamble sentence, malformed JSON with trailing commas, or occasionally something entirely different. If your pipeline passes the raw model output directly to a downstream system that expects valid JSON, you will have production failures.
Output validation at minimum means parsing the expected format and handling parse failures explicitly. For JSON outputs, attempt the parse, detect the failure, and decide: retry the model with a stricter prompt, attempt a correction pass with a second model call, or reject and log the failure. For free-text outputs, validation is about checking that the output meets minimum quality criteria — length, language, absence of refusal phrases, presence of required elements — before passing it downstream.
Schema validation libraries like Pydantic in Python or Zod in JavaScript give you a declarative way to define and enforce output contracts. If you’re building a pipeline that needs to run reliably without manual supervision, using a schema validator on every model output is worth the overhead. Automating content pipelines with n8n and Playwright runs into exactly this class of problem when model outputs feed into automated publishing steps.
Failure State Taxonomy
Not all failures are equal and treating them all the same way produces brittle pipelines. A useful taxonomy for AI pipeline failures: hard failures that should stop the pipeline and alert immediately, soft failures that should trigger a retry or fallback strategy, and silent degradations that should be logged for monitoring without stopping execution.
Hard failures include input contract violations that indicate upstream system problems, model API unavailability, and output schema validation failures that can’t be remediated. These should stop the pipeline, preserve the input for inspection, and generate an alert. Continuing execution after a hard failure produces corrupted downstream state that’s harder to clean up than the original failure.
Soft failures include transient API errors, model outputs that fail schema validation on first attempt but succeed on retry, and inputs at the boundary of acceptable range. These should trigger your retry logic with backoff, not immediate failure. Define your retry budget — maximum attempts, backoff interval, fallback behavior if retries are exhausted — before you need it.
Silent degradations are the hardest to handle. A model that starts returning shorter, lower-quality outputs than baseline without throwing errors is degrading silently. Catching this requires monitoring output quality metrics over time, not just error rates. Build measurement into the pipeline from day one even if you’re not actively watching the dashboards yet.
Idempotency and State Management
An AI pipeline step is idempotent if running it twice on the same input produces the same result without side effects. Most pipeline steps are not naturally idempotent and most engineers don’t think about this until they’re debugging a failure that left the system in a partially processed state. Design for replayability. If a pipeline fails halfway through, you want to be able to restart from the last successful checkpoint without reprocessing completed steps or duplicating outputs.
Checkpointing means persisting state at each successful step boundary. For a pipeline that generates a draft, validates it, formats it, and publishes it, checkpointing at the post-validation step means a failure during formatting doesn’t require regenerating the draft. The cost of writing state to disk or a queue at each step is low compared to the cost of debugging a half-completed pipeline run.
Building AI pipelines that survive production isn’t harder than building ones that work in demos. It just requires doing the engineering work upfront defining contracts, handling failures explicitly, and designing for the inevitable case where something doesn’t go as planned. The happy path is the easy part.