Most AI workflow guides are written by people who tested a few tools for a week and made a listicle. This one is written by someone who built a multi-agent local AI system, watched it collapse, rebuilt it from different principles, and now runs it across six active content sites plus a live QA retainer. The difference between those two kinds of posts is that the second one can tell you what actually breaks.
The AI workflow I run today looks nothing like the one I started with. The early version was tool-heavy, fragile, and dependent on me making decisions that the workflow was supposed to eliminate. Every new AI product that launched got added to the stack. Automations fired in the wrong order. Outputs went places they shouldn’t. The system produced volume but not quality, and the gap between the two was invisible until something went wrong in production. The subtler version of that problem isn’t a broken pipeline. It’s a workflow that technically works but kills the deep work it was supposed to protect. What replaced it is leaner, more deliberate, and built around a single organizing principle: AI handles mechanical work, humans handle judgment. Everything in the current stack either fits that principle or gets cut.
The Problem With Most AI Workflow Advice
The standard AI productivity post gives you a list of tools sorted by use case and tells you to try them. That approach produces a collection of disconnected apps that don’t reinforce each other, create audit trails nobody reads, and get abandoned when the novelty wears off. A workflow is not a list of tools. A workflow is a set of decisions about where work enters, what transforms it, and where it exits. The tools are just implementation details.
The second problem with most AI workflow advice is that it ignores failure modes. Every tool gets described at its best. Nobody tells you that the AI writing assistant that produces clean first drafts in demos will hallucinate citations under deadline pressure, or that the automation that runs perfectly on Monday will fail silently on Thursday because an API changed and nobody set up error handling. Real workflow design accounts for failure states. If your system has no plan for when a step breaks, it will break at the worst possible time, and you will be cleaning it up manually instead of doing the work you automated it to avoid.
The third problem is scale blindness. Most AI workflow content is written for someone managing one project or one job. The constraints change completely when you are running multiple content properties simultaneously, each with its own editorial voice, keyword strategy, and monetization path, while also delivering QA work for a client on a separate pipeline. The tools that work for a single-project freelancer create chaos at that scale unless they are architected deliberately. The question of whether AI actually makes you more productive, or just more busy, is worth examining before you build anything. Whether AI makes you work smarter or just harder is the right place to start that examination.
What My AI Workflow Actually Looks Like
The current stack runs on a Windows desktop using Ollama for local model inference, n8n for workflow orchestration, Notion for structured storage, and Discord as the interface layer for a multi-agent system called Alfred. Cloud models handle tasks that require reasoning quality the local models cannot match. The decision of when to use local versus cloud is not arbitrary: local runs for drafts, reformatting, and repetitive transformations; cloud runs for editorial judgment, complex rewrites, and anything where output quality has direct SEO or client consequences.
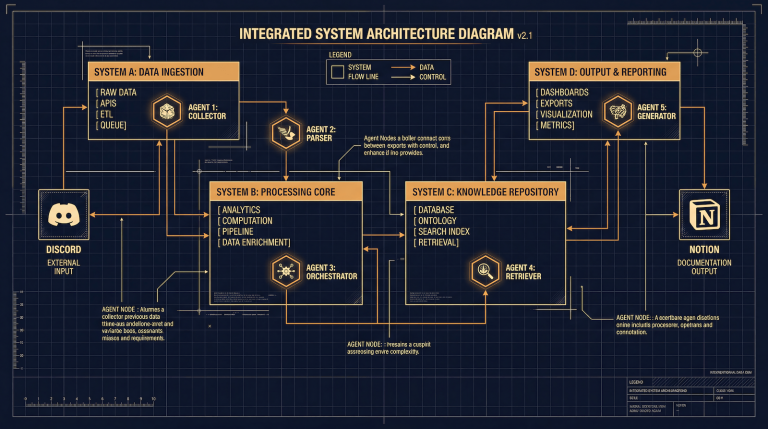
Alfred is organized into four casts, each handling a specific output type. Scribecast handles long-form draft generation. EchoCast handles platform-native reformatting of published posts for syndication. FireCast handles research and brief creation. ReelCast handles video script output. Each cast runs as a folder-based skill architecture with a lean runtime prompt and dynamic companion files loaded by n8n depending on the task. The reason for this architecture is that general-purpose AI assistants degrade fast when you give them too much context at once. Focused skill files keep the model operating inside a defined lane and produce consistent output without constant prompt engineering per task. The full architecture breakdown lives in how I architected a multi-agent local AI system, which covers the design decisions in more detail than this post will.
The drafting pipeline specifically runs through n8n connecting to Ollama, which generates a raw draft saved as a file output. That file gets reviewed and edited before anything goes to WordPress. There is no direct publish step in the automation. AI does not push to production in this workflow. The reasons behind that decision are in why I stopped letting AI push directly to platforms, but the short version is that the error rate on direct-publish automations is unacceptable when you are responsible for the brand signal on multiple sites.
The Writing and Content Layer
The content workflow has three stages where AI touches the work. At the planning stage, AI assists with research clustering, topic gap identification, and generating brief structures from raw ideas. At the drafting stage, Ollama running a local model produces the first draft against a skill file that encodes the site’s editorial rules, voice constraints, and structural requirements. At the syndication stage, EchoCast takes a published post URL, fetches the content, and generates platform-native versions for Dev.to, Medium, LinkedIn, and Facebook without copying the source post. Each output is an editorial reaction piece that cites the canon post, not a reformatted copy of it.
The part AI cannot touch in this layer is editorial judgment. Deciding whether a topic is worth covering, whether an angle is differentiated enough to compete on the SERP, whether a draft actually serves the reader or just fills the word count requirement those decisions require knowing the site, knowing the audience, and knowing what has worked and what has failed over time. AI has none of that context by default, and injecting it through prompt engineering is an ongoing maintenance cost that scales poorly. The practical resolution is that AI drafts and humans decide. The draft is a starting point, not a deliverable.
The QA and Code Layer
The QA side of the workflow is separate from the content side and runs on different tooling. For client retainer work, where I’m the human QA layer on an AI dev team testing live production software, AI assists with test case ideation, Playwright script scaffolding from bug reports, and first-draft documentation. A project management tool handles tickets. The AI does not make release decisions, does not determine severity independently, and does not push scripts to the regression suite without a review pass.
The code layer runs similarly. When building tools or writing automation scripts for Alfred, AI generates scaffolding and handles the mechanical parts of implementation. The decision of what to build, how to architect it, and where the edge cases are stays human. The full decision framework is in when to write code yourself versus let the model do it. The short version: anything that requires understanding the system it integrates with needs human authorship. Anything structurally predictable and repetitive is a candidate for AI generation with a review pass.
Vibe coding works for isolated tools with no production dependencies. It breaks at the integration layer. If the code needs to interact with an existing system, connect to an API, or run in a specific environment, you need to understand both the code and the environment before you can trust what the model produces. How the n8n and Ollama drafting pipeline was built documents exactly where that breakdown happened during Alfred’s build and what the fix required.
What I Cut and Why
The current stack is the result of cutting roughly half of what I started with. Tools that got removed include: a cloud-based AI writing assistant that produced fluent but generic output misaligned with the site voice, an automated social posting tool that published content before the canonical post was indexed, a content calendar AI that created planning overhead instead of reducing it, and several Zapier automations that duplicated work n8n was already handling locally for free.
The pattern across everything that got cut was the same: the tool solved a problem I didn’t actually have, or it solved a real problem in a way that created a larger downstream problem. The automated social posting tool is the clearest example. It saved maybe fifteen minutes per post and cost me several instances of syndicated content competing with the source post before Google had finished crawling it. The time savings did not survive contact with the actual consequences. That calculation, time saved versus cost created, is almost never done honestly before a tool gets added. The hidden costs of AI automation is worth reading before you commit to anything new. Every tool in the current stack earned its place by solving a real problem without creating a new one. That is a higher bar than most AI tool evaluations apply. The pattern of AI creating more work than it eliminates is common enough that it deserves its own diagnosis. Why AI keeps adding work instead of removing it covers what’s usually going wrong when that happens.
The Failure That Rebuilt Everything
The clearest turning point was the autoblog experiment. The short version: I built a pipeline that could go from topic brief to published post with minimal human intervention. It worked technically. It produced posts that were structurally correct, keyword-targeted, and free of obvious errors. What it could not produce was posts that had a point of view, that drew on real experience, or that gave a reader something they could not get from the AI overview on the SERP. The posts were invisible not because the system failed but because the system succeeded at producing exactly what it was built to produce, which was content without a practitioner behind it.
That failure clarified the organizing principle the current workflow runs on. AI can produce the mechanical layer of almost any content or code task faster than a human can. What it cannot produce is the judgment layer, the part that comes from having done the work, failed at it, and figured out why. A workflow that removes the human from the judgment layer does not produce better output faster. It produces faster output with no differentiator, and no differentiator means no traffic, no authority, and no reason for anyone to read it over the next result on the SERP. Everything in the current stack is designed around keeping human judgment in the loop at every decision point that matters.
How to Build a Workflow That Holds
The practical principles from two years of breaking and rebuilding this stack come down to a few things that are not complicated but are easy to skip.
Start with the output, not the tool. Decide what you need to produce, in what volume, at what quality level, and for what purpose. Then find the minimum tooling that gets you there. Adding tools before you have clarity on output creates complexity that compounds faster than it helps.
Separate the mechanical from the judgment. Map every task in your workflow and mark which parts are structurally predictable and which parts require contextual decisions. AI goes in the mechanical column. You stay in the judgment column. Any workflow that puts AI in the judgment column will produce output you cannot trust without reviewing everything, which eliminates the time savings.
Build failure handling before you build scale. This applies to the human side of the workflow too, not just the automation. How AI burnout shows up in remote work covers what happens when the stack runs fine but the operator doesn’t. Every automated step needs a failure state that does not silently corrupt downstream work. An n8n workflow that fails and stops is better than one that fails and continues with bad data. This is basic systems thinking, and it applies to AI workflows the same way it applies to any other automation.
Test locally before connecting to production. Any AI output that can reach a live site, a client deliverable, or a public platform needs a review gate before it gets there. What AI actually replaced in the workflow covers which tasks crossed that gate and which ones didn’t survive the quality bar. For the QA-specific version of that same problem, the structured AI workflow for real testing projects covers how the gate works in a testing context.
The workflow that holds is the one built around what you actually produce, not around what the tools are theoretically capable of. Two things that consistently improve output quality without adding complexity: using voice input to get better results from AI, and recognizing when AI is overcomplicating something that should stay simple. Two years of iteration produced a stack that runs reliably because most of it got cut.