EngineeredAI.net is deindexed on Bing. Every submit, every content fix, every technical correction, still deindexed. My other five sites are growing on Bing. EAI is not. And yet Copilot surfaces EAI articles consistently. The organic index rejected the domain and the AI retrieval layer ignored that rejection and pulled the content anyway. That is the clearest data point I have on why LLM optimization sits on its own track, separate from anything a search engine index controls.
I run six sites. QAJourney, EngineeredAI, RemoteWorkHaven, MomentumPath, HealthyForge, HobbyEngineered. The pattern holds across all of them: AI crawler activity is not correlated with organic search performance. Index status does not gate AI retrieval. Infrastructure does.

What I Am Actually Optimizing For
When I talk about LLM optimization across this network, I mean three specific things. Schema that explicitly identifies what each piece of content is, who produced it, and what it is about. Content structure that leads with the answer and uses heading hierarchy that maps to how questions get asked. Canonical sourcing that makes the original URL unambiguous across every syndication surface so attribution points back to the source regardless of where the crawler first encounters the content.
Those three things determine whether a retrieval system can parse the content cleanly, attribute it correctly, and cite it with confidence. Getting all three right on every post is the actual work. The LLM optimization guide documents how I built this out on EAI from scratch, including what broke early and what the server logs showed once the structure was right. The geographic layer is in the geographic LLM targeting guide.
What I Use to Measure It
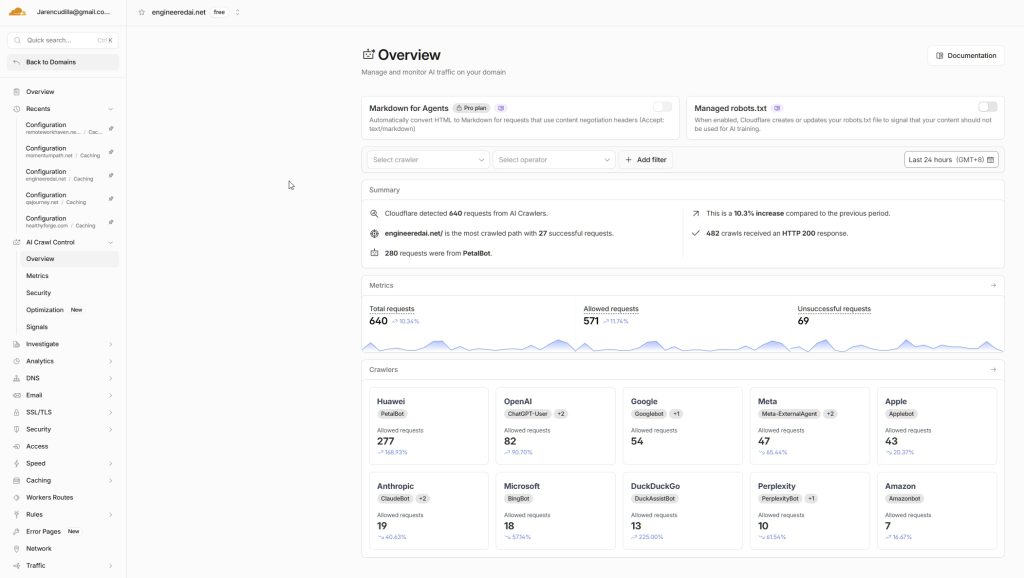
Cloudflare AI Crawl Control is the primary tool. It shows which AI crawlers are hitting the site, at what frequency, which URLs they are requesting, and whether those requests are being served successfully. In the last 24 hours across EAI alone that dashboard showed 640 requests from AI crawlers including OpenAI, Anthropic, Google, Microsoft, DuckDuckGo, Perplexity, Meta, Apple, Amazon, and Huawei’s PetalBot. 571 allowed, 69 unsuccessful. That is the crawler picture. AWStats on cPanel gives additional detail at the server level. If you are on cloud or VPS, raw server logs give you the same data.
For query data I run Google Search Console across all six sites and Bing Webmaster Tools on QAJourney, HealthyForge, HobbyEngineered, MomentumPath, and RemoteWorkHaven. The Bing WMT AI search report is a separate surface from GSC and surfaces different query angles consistently, different phrasing, different intent signals, different topic clusters. Running both gives a more complete picture than either one alone. EAI has no usable Bing WMT data because of the deindex. Cloudflare AI Crawl Control is what I work with for this property and it is enough.
The Tools I Built for This
Schema gets injected manually on every post. The schema generator I built handles Article, FAQ, and HowTo types and outputs clean JSON-LD ready to ship. That is the first check on any new post before it goes live.
Citation readiness is the second check. The AI citation readiness tool audits a URL across heading hierarchy, answer-first structure, entity clarity, and semantic density. A page can have clean schema and still produce poor LLM citations if the content structure makes it hard for a retrieval system to identify the most relevant passage. I run this on posts that are underperforming in crawler activity relative to what Cloudflare AI Crawl Control shows they should be getting.
I am building two more tools in this space for LLM visibility testing and AI answer quality auditing. Not live yet but part of the same workflow once they ship.
Syndication as Infrastructure
Every post syndicates to GitHub Gists with canonical links back to the source URL, Dev.to, Medium, LinkedIn, and Hashnode. The canonical link on every syndicated version points back to the original. That is not a distribution strategy, it is an attribution infrastructure. When a crawler encounters the content on any of those platforms the canonical source is unambiguous. That is what prevents the Blogorama problem from repeating, where scraped content gets attributed as the original because the canonical chain was broken.
What Google LLM Optimization Specifically Means
Google AI Overviews run on the same infrastructure requirements as every other retrieval surface: clean schema, answer-first structure, clear entity attribution. The difference is that Google’s trust framework still applies to which sources get pulled into overview responses, which means domain signals that do not affect GPTBot or ClaudeBot do affect Google AI Overviews. On EAI that is a constraint. On the other five sites in the network it is an active channel confirmed by both GSC and Bing WMT AI data showing those properties surfacing in AI-generated responses across Google, Bing, Yahoo, and DuckDuckGo from the same optimization effort.
The queries landing on EAI include “google llm optimization” as a distinct phrase, which signals that part of the audience is thinking specifically about Google’s AI surfaces. The infrastructure work is the same regardless of which surface you are targeting. What changes is which tool shows you whether it is working.
This Is Also a Billable Service
The same infrastructure work that improves LLM visibility on your own sites is something other businesses need and are not getting done. The query data on EAI shows searches around starting an LLM optimization business, which tracks with what the market looks like right now. The supply side is thin. How to build that service and what delivering it actually looks like is covered over on RemoteWorkHaven.