ChatGPT is the default for most people who use AI assistants because it was first and it’s good. It’s also a cloud service that sends everything you type to OpenAI’s servers, costs money at scale, and breaks your workflow when the API goes down. Local alternatives to ChatGPT exist and some of them are genuinely good. The question is whether they’re good enough for your specific use case, because the honest answer varies depending on what you’re trying to do.
Running a local alternative to ChatGPT means accepting some tradeoffs upfront. You’re responsible for setup and maintenance. Model updates require manual action. The best local models are behind the frontier models on reasoning and knowledge tasks. If those tradeoffs are acceptable given what you get in return such as privacy, no API costs, offline capability, and full control over the model then the current generation of local models is worth serious consideration. Choosing the right local model for your GPU is where most people should start before anything else.
The Practical Stack
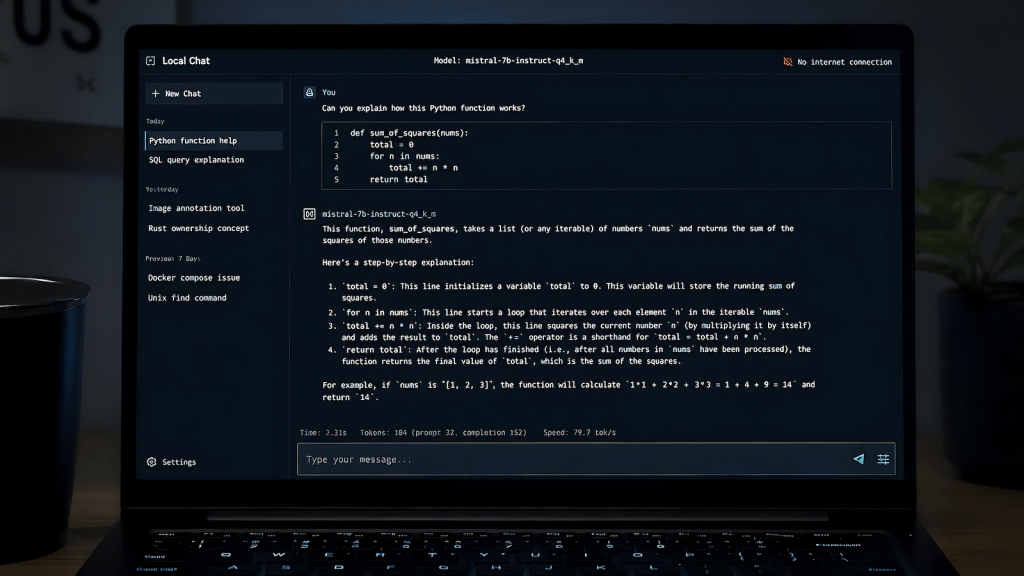
Ollama is the right starting point for running local models because it handles model management, quantization selection, and a local API server with minimal configuration. Install it, pull a model, and you have a local ChatGPT-equivalent accessible via a web interface or API. The management overhead compared to running llama.cpp directly is worth it for most users who aren’t doing edge deployments. Setting up Ollama with LiteLLM on Windows covers the full setup process for a Windows environment.
The model selection question matters more than the tooling question. Llama 3.1 8B, Mistral 7B, Qwen 2.5 7B, and Gemma 2 9B are all competitive at the 7-9B parameter range and run comfortably on consumer GPUs with 8GB of VRAM at 4-bit quantization. For general assistant tasks like drafting, summarization, Q&A, light coding help, the quality difference between these models and GPT-3.5 level is minimal for most practical work.
Where Local Models Hold Up
Writing assistance is the strongest use case for local alternatives. Drafting, editing, rewriting, summarizing, and formatting text are all tasks where current local 7B-8B models produce output that’s competitive with cloud alternatives. The feedback loop is faster because there’s no network latency, and you can keep sensitive documents on your machine without a data handling concern.
Code assistance at the level of autocomplete, explanation, and simple generation is another solid fit. Models like Qwen 2.5 Coder and DeepSeek Coder are specifically trained on code and outperform general-purpose models on programming tasks within their capability range. They’re not replacing a senior developer’s judgment on complex architecture decisions, but for the daily mechanics of writing and debugging code they’re genuinely useful.
Document analysis and Q&A over local files works well with a RAG setup. Feeding your own documents into a local pipeline using context engineering approaches lets you ask questions about internal documentation, meeting notes, or research materials without sending that content to an external service.
Where They Fall Short
Current knowledge is the most significant gap. A local model’s knowledge is frozen at its training cutoff, and there’s no browsing capability unless you build one explicitly. Anything requiring recent information, current events, updated documentation, recent research requires a different solution. This isn’t a dealbreaker for most workflows but it is a real limitation that cloud alternatives handle better.
Complex multi-step reasoning is still better on frontier models. If you’re doing work that requires sustained logical reasoning across many steps, ambiguous problem solving, or synthesis across a wide knowledge base, the 7-9B local models produce more errors and require more prompt engineering to stay on track. The gap narrows as model sizes increase but a 70B model requires hardware most people don’t have.
The practical answer for most users is a hybrid approach: local models for the majority of daily tasks where privacy and cost matter, cloud access reserved for tasks that genuinely require frontier capability. That’s a more defensible stack than full cloud dependency and it costs less.