The pitch for fully automated AI publishing is simple: write once, let the system handle everything else. The post gets drafted, formatted, scheduled, and pushed to every platform while you sleep. No manual steps, no bottlenecks, no babysitting. It sounds like the right way to run a lean content operation.
It is not. The ai auto-publish to platforms problems are not edge cases. They are the default behavior of any system complex enough to touch multiple platforms, and they compound silently until something visible enough to notice finally breaks. By the time you find the problem, it has already been live for hours, sometimes longer.
I know this because I built two systems that did exactly this. Both collapsed. Neither told me they were collapsing.

What ai auto-publish to platforms problems actually look like
The failure modes are not dramatic. There is no error screen, no notification, no alert. The system just keeps running, except now it is running wrong.
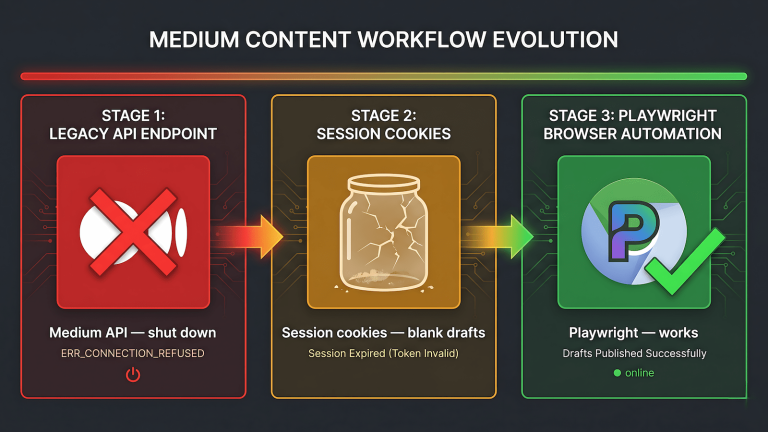
A post goes live on Medium with the formatting from a different draft. A Dev.to entry publishes with the internal metadata still in the body copy. A WordPress post fires with an empty featured image slot because the image upload step timed out silently and the workflow continued anyway. None of these are hypothetical. These are things that happened inside my own pipelines, documented in the autonomous AI publishing pipeline lessons post I wrote after the first major collapse.
The deeper problem is that platforms do not behave consistently. What works in one authentication session breaks in the next. What Playwright handles cleanly in a dry run fails in production because the platform updated its DOM. What n8n queues correctly at 2am pushes incorrectly at 6am because a rate limit kicked in and the retry logic sent the same post twice. The n8n content syndication automation build taught me this the hard way: the more platforms you add, the more failure surfaces you are managing, and the harder each failure is to trace back to its source.
The scope problem nobody talks about
The issue is not that AI tools are unreliable. Most of the tools I used did exactly what they were designed to do. The issue is that automated publishing asks those tools to do something they were never designed for: be the final gatekeeper on live content.
AI drafts well. AI formats consistently. AI can queue, schedule, and trigger. But AI cannot notice that a post about content systems went live on a gaming forum because a tag was misconfigured. It cannot catch that the version that published was the rough draft, not the final. It cannot tell the difference between “this is ready” and “this is next in the queue.” That distinction requires human judgment, and the moment you remove the human from the publish step, you remove the only part of the system that actually understands context.
This is the core of what the structuring AI pipelines around inputs, outputs, and failure states framework tries to capture: every step in a pipeline needs a defined success state. Publishing to a live platform is a step with no good automated success check. The post either looks right to a human or it does not. There is no automated assertion that catches “this looks weird.”
What broke and when
AutoBlog was the first build. The premise was fully automated: Ollama generates the draft, n8n formats and publishes it, the whole loop runs without me. It worked in testing. In production, it produced posts that were technically live and technically wrong. Formatting inconsistencies, content that had not been through editorial review, metadata that did not match the post body. The n8n + Ollama local AI drafting pipeline is the cleaner version of what came after AutoBlog died, but even that version had a human gate added back in before anything touched a live platform.
EchoCast was the second attempt. Instead of drafting, EchoCast handled syndication: take a published WordPress post, reformat it for each platform, push it out. The formatting logic was solid. The platform authentication was not. Sessions expired. The system retried. Posts doubled on some platforms, failed silently on others, and one ended up published with a platform-specific header block that made no sense in context. The automation was doing exactly what it was told. What it was told was not sufficient.
Both systems collapsed under their own weight because they were optimized for throughput, not reliability. Every added platform was another failure surface. Every automation step was another place where silent failure was possible. The more I scaled the pipeline, the further I got from the thing that actually mattered: a post that a human has looked at before it goes live.
What trigger-based, human-in-the-loop looks like instead
The rebuild, which became Alfred, is built on a different principle. AI handles the parts of the workflow that do not require judgment: drafting, formatting, structuring, suggesting. Humans handle the parts that do: reviewing, approving, and pushing the button.
This is not a limitation. It is a feature. The ai overcomplicates simple tasks problem is real: the instinct to automate every step of a process because automation is available leads to systems that are harder to maintain than the manual process they replaced. A trigger-based architecture means the system does not move to the next step until a human says it should. The draft is ready when I say it is ready. The post goes live when I publish it.
The practical result is that Alfred generates drafts I paste manually into WordPress. EchoCast produces platform-formatted files I review before posting. Nothing touches a live platform automatically. The throughput is slightly lower. The error rate is near zero. The tradeoff is obvious when you have already cleaned up the alternative.
The rule: AI drafts, humans ship
The ai auto-publish to platforms problems are not going to be solved by better tooling. They are structural. Every platform has inconsistent behavior. Every authentication session has an expiry. Every automated step has a failure mode that the system will not tell you about unless you build explicit checks for it, and even then, the checks are only as good as what you thought to check for.
The answer is not to build better automation. The answer is to stop asking automation to do the job that human judgment exists to do. Use AI for what it is actually good at: generating, structuring, and formatting content at scale. Keep the publish step in human hands. The extra thirty seconds it takes to hit publish manually is the cheapest reliability improvement you can make to any content pipeline.
The what AI replaced in my workflow post covers the broader picture of where AI actually earns its place in a solo operation. Publishing is not one of those places. Not yet.