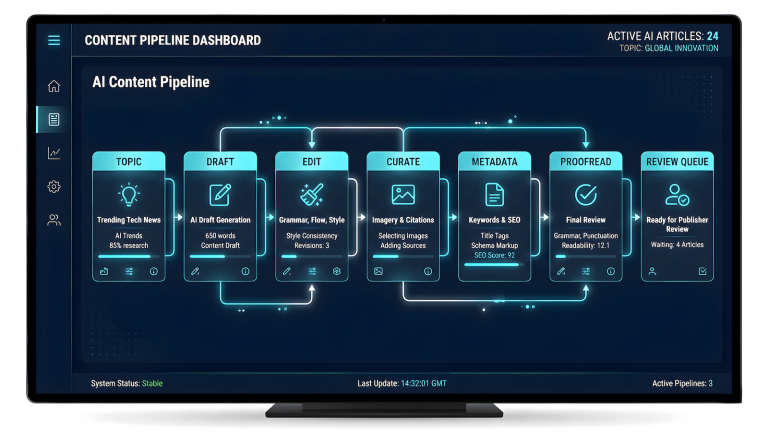
An AI content workflow that actually works is not the one that produces the most output. It’s the one that doesn’t silently break your site, tank your rankings, or ship content that reads like it was written by someone who has never encountered the topic in real life. Two years of running six blogs on a single content operation with AI assistance at every layer has produced one consistent lesson: the pipeline is the product, and most pipelines have no quality gate.
This cluster documents what that looks like when it’s working and what it looks like when it isn’t.
Why Most AI Content Workflows Fail
The failure mode isn’t output quality. Most AI writing tools produce grammatically correct, coherent text. The failure mode is that the output is correct and hollow, formatted for a reader who doesn’t exist, optimized for queries nobody types, and indistinguishable from the ten other posts already ranking for the same phrase.
AI-generated SEO content is the clearest example of this pattern at scale. The tools promise faster ranking. What they produce is faster indexing of content that doesn’t hold position because it has no practitioner layer, no specific detail, and no reason for a reader to stay. Google has seen enough of this content to recognize it, and so have readers.
AI promised to fix WordPress SEO and broke everything instead is a real production case study of what happens when you hand an AI tool access to your site’s SEO settings without understanding what it’s doing. The categories broke. The SQL queries failed. The cleanup took longer than the problem it was supposed to solve. This is not an edge case. It’s the typical outcome when AI tools are applied to systems the operator doesn’t fully understand.
What an AI Content Workflow Actually Needs
Clarity, context, and editorial judgment are what separate content that holds position from content that ranks briefly and drifts. AI can produce volume. It cannot produce the practitioner detail, the honest assessment, or the specific example that makes a post irreplaceable. That layer has to come from the operator.
The multi-model AI writing stack that runs this network evolved over two years of breaking single-model approaches. ChatGPT 3.5 was the starting point. One model, one pipeline, everything through the same tool. That system ran until the output quality became a ceiling. The current stack runs Claude for reasoning and structure, with human curation gates between every stage. Not because the models aren’t capable. Because the gates are where quality actually gets enforced.
Building a repeatable SEO system across five blogs is the architecture layer that makes the writing layer sustainable. Meta keywords, internal linking logic, cluster structure, and hub architecture are the infrastructure that gives AI-assisted content somewhere to land. Without that infrastructure, content volume compounds the problem instead of solving it.
Automation: What to Build and What Not To
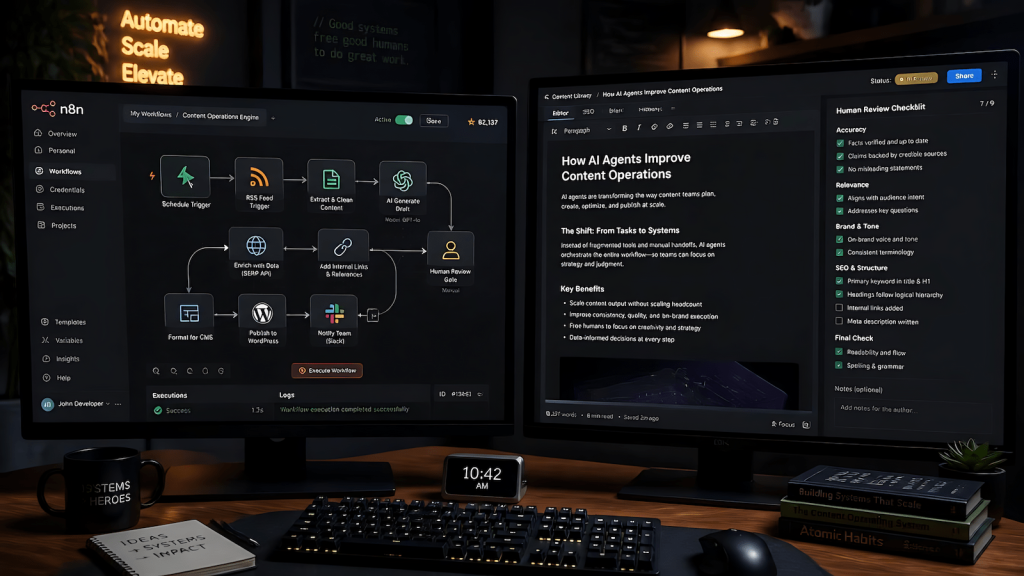
The autonomous AI blogging engine built on Python, n8n, and a multi-stage pipeline is real and it runs. The lesson from running it is not that automation is bad. It’s that automation without a human review gate ships errors confidently and at scale. The pipeline that runs without oversight is the pipeline that publishes the wrong category, breaks the internal link structure, or produces a post that answers a question nobody asked.
n8n and Playwright content syndication is the distribution layer, not the creation layer. The distinction matters. EchoCast handles moving a finished, human-reviewed post to its syndication targets. It does not generate content. The automation is downstream of quality, not upstream of it.
Persistent browser session automation solves a specific problem: logging in on every automation run gets flagged and breaks. The persistent context approach keeps sessions alive across runs without triggering platform authentication responses. That’s a real operational problem with a real engineering solution, not a productivity tip.
The n8n Playwright automation post is the most technically specific piece in this cluster and the most viewed. n8n cannot drive a browser natively. The three approaches (Execute Command node, community node, persistent Express server) have different failure modes and the only one worth running in production is the Express server approach. That’s the kind of specific that AI overviews cannot replicate.
The Video and Search Layer
Building a local video scripting pipeline without paying for a single tool applies the same principle to video production: Ollama for scripts, Edge TTS or Kokoro for voiceover, Pexels API for footage, ffmpeg for assembly. The whole stack runs locally with no subscription fees. The output is not broadcast quality. It’s functional video content that documents real work without the overhead of a paid production stack.
AI-powered search and how it’s changing information discovery is the context layer for why the content workflow question matters at all. If AI search is increasingly the first surface readers encounter, the content that gets cited is the content with structure, specificity, and clear entity signals. The workflow that produces that content is not a faster version of the old workflow. It’s a different discipline.
Where to Go From Here
If you’re building a content pipeline for the first time: My Multi-Model AI Writing Stack and Building a Repeatable SEO System
If your AI content is hurting your rankings: AI-Generated SEO: Ranking Fast, Thinking Less and You Don’t Need AI to Rank
If you’re automating distribution: n8n + Playwright Content Syndication and Persistent Browser Sessions for Content Automation
If you’re building the automation layer: Autonomous AI Blogging Engine and n8n Playwright Automation