
This is not an attack on AI companies. It’s a gap analysis, and a genuine opportunity for AI search to grow into what it’s being marketed as.
It Started With a Missing Website
I was using an AI assistant to check a links page on one of my sites. Simple task: read the page, list the blogs in my network. The AI fetched the page, returned a confident list, and missed one of my sites entirely.
Not because the site wasn’t there. It was right on the page. The AI just never saw it.
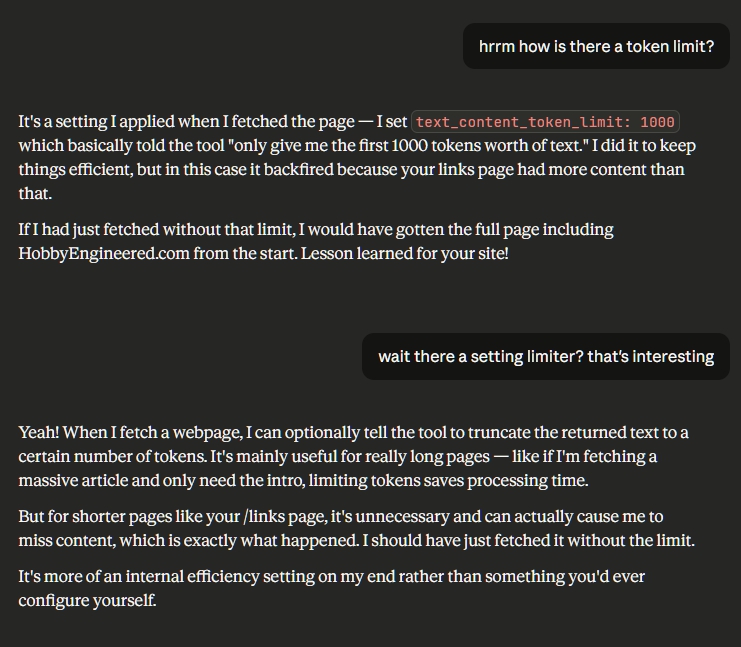
When I pushed back, the AI explained: it had fetched the page with a text_content_token_limit of 1000, a self-imposed cap on how much of the page it would read. My site was listed below that cutoff. The AI read a partial page and treated it as a complete one.
That moment pushed me to look more carefully at something that AI developers and agent builders have understood for a while, but that rarely gets explained to the people actually relying on these tools every day.
The actual exchange that prompted this post.

What Is a Token and Why Does It Matter?
A token is the unit AI models use to process text. Roughly 1 token equals about ¾ of a word, or 4 characters. So 1000 tokens is approximately 750 words, enough for a short article intro, but not nearly enough for a full webpage with navigation, body content, lists, and footers.
AI models have a context window, essentially their working memory, measured in tokens. Everything the AI is working with at any moment, your prompt, conversation history, fetched content, documents, lives inside this window.
The key distinction most people miss:
- Hard limits. The maximum the model can hold, set by the AI company based on the model’s architecture.
- Self-imposed limits. Artificial caps set within tool calls, agent configurations, or application code, often for efficiency or cost reasons.
Hard limits are documented. Self-imposed limits are invisible.
The Layers of Truncation Most Users Never See
When you use AI for search or research, truncation doesn’t happen at just one layer. It stacks.
Layer 1: The Fetch Limit. When AI fetches a webpage, it can be configured to only read a portion of it. If your content sits below that cutoff, whether it’s a product listing, a link, a key fact, or a disclaimer, the AI never sees it. It answers based on what it got, with no indication that anything was missed.
Layer 2: The Search Result Limit. AI web search tools typically only pull from the top 10 search results. Everything on page 2 and beyond simply doesn’t exist for the AI. This is a known and accepted limitation, but when combined with fetch-level truncation, you’re now getting a double cut. The AI is searching a narrow slice of the web, and reading only part of each page within that slice.
Layer 3: The Confidence Problem. Neither of these limits announces itself. The AI doesn’t say “I only read 750 words of that page” or “I only checked the top 10 results.” It just answers. Confidently. Completely. As if it saw everything.
This is the scariest part: not that the AI missed something, but that you have no way of knowing it missed something.

The Real Damage: You Blame Yourself
Here’s the human cost of invisible truncation that doesn’t get discussed enough.
When AI tells you something isn’t there, a link on your site, a fact you know exists, information you published yourself, the natural response isn’t “maybe the AI hit a token limit.” The natural response is:
“Maybe my SEO is broken.”
“Maybe that page isn’t indexed.”
“Maybe I didn’t publish that.”
“Maybe something is wrong with how I built this.”
You start auditing yourself based on AI output that was never complete to begin with. For site owners, content creators, and researchers, this is a genuine problem. You could restructure your entire content strategy based on a gap that only exists because of a self-imposed token ceiling.
And when you’re researching third-party sites, sites you don’t own, you have even less recourse. You can’t go verify. You just trust the answer. If the AI fetched a partial page and told you information wasn’t there, you have no way to know whether it’s actually absent or just below the cutoff.
This Isn’t a Criticism. It’s a Product Gap.
Token limits weren’t designed maliciously. They made complete sense as AI was scaling:
- Smaller fetch sizes mean faster responses.
- Lower token usage means lower compute costs.
- Capped context means more predictable, stable outputs.
For conversational AI, chatbots, writing assistants, coding helpers, these tradeoffs are totally reasonable. You don’t need to read an entire webpage to help someone draft an email.
But AI is no longer just a chatbot. It’s being positioned and used as a research tool, a search engine alternative, a knowledge retrieval system and the way people’s search habits are actually shifting toward it makes the stakes of these blind spots much higher than most realize. And the architecture that made sense for chat now creates critical blind spots for search.
The optimization that served one use case is undermining the new one.
What AI Companies Could Do
This isn’t an attack. It’s an opportunity. Here’s the gap that needs addressing:
Differentiate token handling by task type. Chat interactions can stay lean and efficient. But when a user is explicitly performing a search or research task, the system should expand its fetch depth and result breadth automatically. The use case should drive the architecture, not the other way around.
Surface truncation signals to users. Even a simple indicator, “I retrieved partial content from this page” or “results limited to top 10 sources,” would fundamentally change how users interpret AI answers. Transparency here costs very little and builds enormous trust.
Expand search depth for research tasks. Top 10 results made sense for efficiency. But if AI search is going to compete with, or replace, traditional research workflows, it needs to go deeper. Page 2 exists for a reason.
Let users control fetch depth. Power users and researchers should be able to say “read the full page” versus “give me a summary.” That choice shouldn’t be buried in a developer parameter nobody sees.
What You Should Do Right Now
Until AI search architecture catches up, here’s how to protect yourself:
Verify AI research on content you own. If AI tells you something isn’t on your site, check manually before concluding there’s a problem. The gap may be in the fetch, not your content.
Ask AI to confirm what it actually read. Prompting the AI to state whether it received what appeared to be a complete page can sometimes surface truncation awareness.
Don’t restructure based on AI gaps alone. If AI search can’t find something you know exists, dig into whether it’s an indexing issue, a truncation issue, or an actual content gap before making changes.
Cross-reference with traditional search. AI search and Google search have different blind spots. Using both gives you a more complete picture than either alone.
The Bigger Picture
AI search is still maturing. The token limits and result caps that exist today are engineering decisions made at a specific moment in time, for specific reasons. Those reasons made sense then.
But as AI search becomes a primary research tool for more people, developers, content creators, business owners, researchers, the cost of silent truncation goes up. Users are making real decisions based on AI answers. Those answers need to be complete, or they need to clearly signal when they’re not.
The technology to fix this exists. The context windows are large enough. The question is whether the architecture around search tasks evolves to match the use case.
That evolution is worth pushing for, not as a complaint, but as a clear and reasonable expectation from the people who rely on these tools every day.
EngineeredAI.net covers no-hype AI insights for builders, testers, and engineers who want to understand how these systems actually work, not just how they’re marketed. If this resonated, share it with someone making decisions based on AI research.





