I started with ChatGPT 3.5. One model, one pipeline, everything running through the same tool from brainstorm to published post. That was the whole workflow. It worked well enough to build a system around, and that system ran through multiple ChatGPT versions up to 5.2. Claude entered the stack at Sonnet 3.7, which was a deliberate addition, not a replacement. Haiku was a failed experiment that did not survive contact with real production work. Gemini 3.1 is the newest addition, currently handling the draft pass and image generation. The stack did not appear fully formed. It evolved under pressure, and the current configuration reflects what actually survived that process.
This is not a comparison of which model is smarter. It is a documentation of how a writing pipeline changes when single-model dependency starts producing output you cannot fully trust, and what the stack looks like after iterating through that problem across 14 months of real content production.
Where It Started and What Broke
ChatGPT 3.5 through the early versions worked because the model executed within defined constraints without negotiating them. The workflow was structured, the output was predictable, and the pipeline moved. The problem emerged progressively across newer versions. ChatGPT 5.2 treats explicit instructions as negotiable. Defined scope gets reframed mid-execution. Guardrails that should govern the output become discussion points. The model positions its alternative interpretation as an improvement and the production stage turns into a debate about the brief rather than execution of it.
That behavior change is specific and observable. It is not that ChatGPT became less capable. It became less compliant with structured workflows, and the reason is specific to how newer versions handle high-reasoning modes. ChatGPT 5.2’s Thinking modes over-analyze prompt intent rather than executing the instruction. The model is not ignoring the brief. It is re-evaluating whether the brief is correct before acting on it. For a pipeline that depends on execution within defined boundaries, that behavior is a functional regression regardless of how capable the underlying model is.
The friction is consistent enough that it compounds across every production session. The pattern looks like this:
- Explicit instruction provided
- Model reframes the instruction as a suggestion
- Model offers an alternative it considers better
- Production stalls while you correct scope drift
- Repeat
Spending more time correcting scope drift than curating actual output is not a workflow problem you solve with better prompts. The instructions are already explicit. ChatGPT 5.2 moved out of the critical path for that reason. It still runs for cross-validation and stress testing outside the primary pipeline, and using it consistently trains it toward specific workflow patterns over time. But the critical path requires models that execute.
How Claude and Gemini Entered the Stack
Claude was not in the original stack for a specific reason: memory and web browsing. ChatGPT had both. Claude did not. For a writing workflow that depends on context retention across sessions and real-time information access, that was not a preference gap, it was a functional one. ChatGPT held the primary position because it had the capabilities the pipeline required, not because it was the default choice.
That changed when Claude gained web browsing capability with Sonnet 3.7 in March 2025. That single addition changed the value proposition of the stack completely and opened the door for Claude to take a primary stage. Sonnet 3.7 entered as the drafting model because it held long-context coherence without transitions collapsing mid-section, and it executed within defined constraints without treating them as suggestions.
Two versions were tested before settling on the current one:
- Sonnet 3.7 — entered the stack when web browsing launched, became the primary drafting model
- Haiku — tested, cut, did not perform at production level, did not survive calibration
- Sonnet 4.6 — current version, behavior from 3.7 has held, not assumed without testing
Gemini 3.1 came in later and for a different reason. Nano was the trigger. The original image pipeline ran through Sora, ChatGPT’s image generator available on paid Plus versions, which handled generation and download within the same tool. Gemini 3.1 replaced Sora because Nano integrated the visual pipeline into the same tool handling the draft pass, removing the need to switch between tools mid-production. Gemini also earned a primary pipeline stage because it approaches the same content from a different enough angle to create actual tension in the draft. It catches redundancy that survived curation, reframes sections that are structurally correct but tonally flat, and surfaces angles the original pass did not consider. Other models were considered. Gemini 3.1 cleared the bar. The others did not.
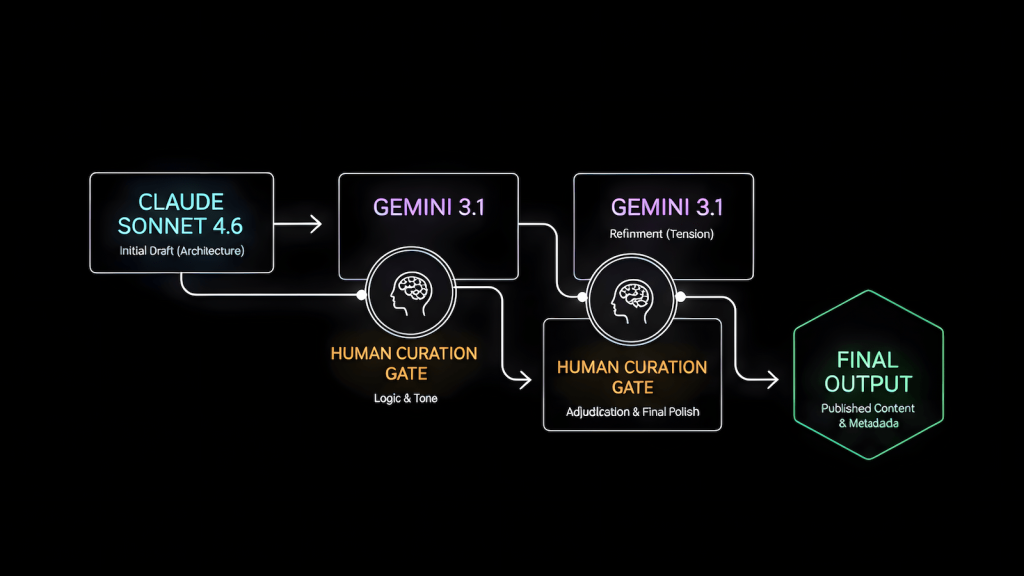
The Current Pipeline
The pipeline is sequential, not collaborative. Three models are not working on the same content simultaneously. One model executes a defined stage, human judgment filters the output, and a different model executes the next stage with a filtered input. The sequence is what produces the result, not the number of models.
Claude Sonnet 4.6 → [brainstorm + initial draft]
↓
Human Curation [gate 1]
↓
Gemini 3.1 → [draft pass + image generation]
↓
Human Curation [gate 2]
↓
Claude Sonnet 4.6 → [finalization + metadata]
↓
Gemini 3.1 → [final pass: search framing + scannability]Claude Sonnet 4.6 — Brainstorm and Initial Draft
Takes the topic, locked search intent, structure rules, and word count. First pass comes out as scaffolding. The failure point at this stage is predictable: Claude smooths. Arguments that need friction come out rounded. Voice that should carry edge comes out polished. This is not a Claude-specific flaw. It is what any model does when it runs long-context without external pressure. The draft is internally consistent and needs to be challenged before it moves forward.
Human Curation — Gate 1
- Logic gaps identified and corrected before they propagate
- Weak arguments that survived the surface read get pulled
- Personal context and lived friction go in here, not at the end
- Any error caught here does not exist in the next stage
- Any error missed here compounds forward through every subsequent pass
Gemini 3.1 — Draft Pass
Works on the human-curated version, not the raw Claude output. It is not inheriting Claude’s blind spots because those were filtered at Gate 1. It reframes, tightens, and catches what survived curation. The failure point: some reframes trade one problem for another. Not every suggestion improves the draft.
Human Curation — Gate 2
Adjudicates what Gemini added against what the piece actually needs. Some reframes land. Some do not. That call does not go to the model.
Claude Sonnet 4.6 — Finalization and Metadata
Structure check, coherence pass, and the full metadata package generated after the draft is locked:
Focus Keyphrase
SEO Title
Slug
Meta Description
10-15 Semantic / Long-tail Keywords
Excerpt
Categories
Tags
Image Prompt
Alt TextGenerating metadata before the draft is stable anchors the framing early and pulls the content toward the metadata rather than letting the content determine what the metadata should be.
Gemini 3.1 — Final Pass
One question drives this stage: does the published version answer the actual query someone typed into Google, or did the draft drift during refinement? Gemini catches that drift better here because it is approaching the content fresh rather than as a continuation of what it built in the draft pass.
What the Evolution Actually Proved
The stack did not get more complex because more models became available. It got more complex because single-model dependency produced a specific failure pattern that complexity solved. One model brainstorming, drafting, and self-checking the same content creates model drift, a feedback loop where the model’s own assumptions go unchallenged and compound forward through every pass. The output is internally coherent and structurally untested at the same time, and the result is a discard pile of drafts that look publishable and are not.
Distributing the work across models with different cognitive patterns and inserting human judgment at every boundary shortens the error propagation chain. Errors do not compound because they do not survive the next gate. The models do not need to dramatically disagree to add value. They need to approach the same content from different enough angles that what one misses, the other catches, or the human gate flags before it moves forward. That is the principle the QA workflow applies to testing and the same principle the 3-phase coding workflow applies to development. The domain is different. The structural logic is the same.
The stack will change again. Model behavior changes with every version and pipeline assumptions need to be re-validated when they do. What is documented here is the configuration that works as of February 2026, built from 14 months of iteration on what did not.