
I had never written a line of Python before this.
I want to be clear about that upfront because everything that follows depends on it. I did not build AutoBlog AI because I am a developer. I built it because I had a conversation with Claude, understood what I wanted to happen, and pushed until the system existed. The code is Claude’s. The architecture decisions, the feature list, the provider choices, the quality gates, all of it came out of a back-and-forth that ran for hours and covered everything from whether to use Flask to whether Ollama would be worth the hardware tradeoff on a mid-range laptop.
I know what this sounds like. I wrote about this exact trap, that letting AI write code you do not understand is how you end up maintaining a system you cannot debug, explain, or extend. I meant it then and I mean it now. This post is where I prove I did not fall into it.
There is a version of AI-assisted building that is not vibe coding, and I think people are still confusing the two.
This post documents how that happened, what we decided and why, and what AutoBlog AI actually does across three versions that evolved in the same conversation.
The Starting Point Was My Own Writing Stack Post
I had just published the multi-model writing stack breakdown, the one documenting 14 months of iterating a sequential Claude and Gemini pipeline with human curation gates at every boundary. That post existed because the workflow was real and worth documenting.
Reading it back, I had one obvious question: how much of this can run without me?
Not all of it. The human curation gates are the whole point. Errors do not compound because they do not survive the next gate. But the mechanical parts, topic research, drafting, refinement, metadata generation, publishing, those are executable steps. If you can describe a stage precisely enough for a human to follow, you can describe it precisely enough for a model to execute.
So I asked Claude to help me build it.
Learning Python by Watching It Get Written
Here is what learning Python looked like in this context: Claude wrote the code, I read it, I asked questions about the parts I did not understand, and I watched the architecture take shape in real time.
That is not the same as learning Python from a course. I cannot write a Flask route from scratch. But I can read one and understand what it does. I can follow the data flow. I can see where a stage hands off to the next stage and understand why the output of one becomes the input of the next.
What I actually learned:
- Flask is just a server. Routes are just functions that run when someone hits a URL. That is the whole thing.
- The config.json pattern. Every setting lives in one file. The app reads it on every request. Change the file, the app picks it up. No restarts.
- API calls are just HTTP requests. Every AI provider works the same way underneath. You send a message, you get text back. The wrapper libraries just clean up the syntax.
- Threading is why the scheduler works. One thread runs Flask. Another thread runs the scheduler loop in the background. They share the same config file. That is the whole architecture.
None of this required formal Python knowledge. It required understanding what the code was supposed to do and following the logic until it made sense. That is the difference. A vibe coder runs the code and hopes it works. I read it until I could explain every decision to someone else.
The Model Conversation, What We Actually Decided (v1)
This is the part most people skip when they document a build. They show the final stack and not the reasoning that produced it. The reasoning is the interesting part.
We started with Claude and Gemini because that is what my existing stack used. Claude for the heavy reasoning stages, Gemini for the faster refinement and SEO passes. That was the obvious starting point.
Then I asked the obvious question: do I need to pay for Claude?
The answer was no, not to start. The free stack, Groq and Gemini, covers all five pipeline stages with zero cost. Groq’s Llama 3.3 70B is fast, executes instructions precisely, and handles the strategic stages well. Gemini 2.5 Pro handles the drafting and finalization. Gemini 2.0 Flash handles the SEO pass where speed matters more than depth. That combination runs an entire article pipeline for free.
Claude stays in the stack as an upgrade path. When I am ready to pay for it, I change a dropdown per stage. No code changes.
The four test sites are configured and ready:
- momentumpath.net, personal development, productivity, mindset
- remoteworkhaven.net, remote work, freelancing, digital nomad
- healthyforge.com, health, fitness, wellness
- hobbyengineered.com, PCs, gaming, consoles, mobiles
Each site has its own AI author account. Alfred handles health and tech content. Edwin handles productivity and remote work. They are both WordPress author accounts with application passwords. Neither of them is a real person and I am not pretending otherwise.
Expanding the Model Roster (v2)
The first version worked. Then I pushed it further.
The v2 conversation was about provider diversity. One provider going down, hitting rate limits, or changing their free tier should not take the whole pipeline offline. The solution was to support every viable provider and let each pipeline stage use a different one if needed.
We added four more providers in v2, each for a different reason.
Mistral approaches the same content from a different angle than Llama or Gemini. Mistral Small is free. Mixtral 8x7B is free. Mistral Large costs money but performs at a level that justifies it for finalization stages. The free tier is enough to start.
OpenRouter is the sleeper of the group. One API key gives access to fifty-plus models, many of them free. DeepSeek R1 for free. Phi-4 for free. Gemma 3 27B for free. The practical value is that when a new model drops and performs well, it appears on OpenRouter immediately. I do not need to add a new provider integration. I just pick it from the dropdown.
Ollama runs models locally with no API, no cost, and no internet required after the initial download. I have a Legion 5 laptop with a 3050 Ti. The 3050 Ti has 4GB VRAM, which is enough for Phi-4 and quantized Mistral 7B but not Llama 3.3 70B. That model needs 40GB VRAM to run fully on GPU. Knowing this matters because gaming performance and LLM inference use GPU resources in completely different ways. Gaming streams assets dynamically while LLMs need the entire model loaded into VRAM at once and kept there for the full inference. The 3050 Ti can run Spider-Man Remastered because it streams textures efficiently. It cannot run Llama 3.3 because it cannot hold 40GB in 4GB of memory. Understanding why it works for some models and not others is the difference between debugging a misconfiguration and blaming the tool.
Claude is kept as a paid upgrade path. When quality on the free stack is not good enough, swapping one stage to Claude Sonnet changes the output ceiling immediately.
The final model roster in v2 covers twenty models across six providers. Every pipeline stage has a dropdown. The default setup is Groq and Gemini at zero cost.
Adding Quality Gates and a Review Queue (v3)
The v2 conversation surfaced the real risk clearly. Four sites publishing three times a day is 168 posts in two weeks of pure AI content. These are not new domains. All four sites are over a year old with existing content and real traffic history. But Google’s helpful content systems are tuned to catch sudden content velocity spikes regardless of domain age, and flooding established sites with unreviewed AI output is a risk I was not willing to take without quality gates in place first.
The answer was not to stop automating. The answer was to build better quality gates into the pipeline itself and slow the publishing rate down to something that looks like a real blog finding its feet.
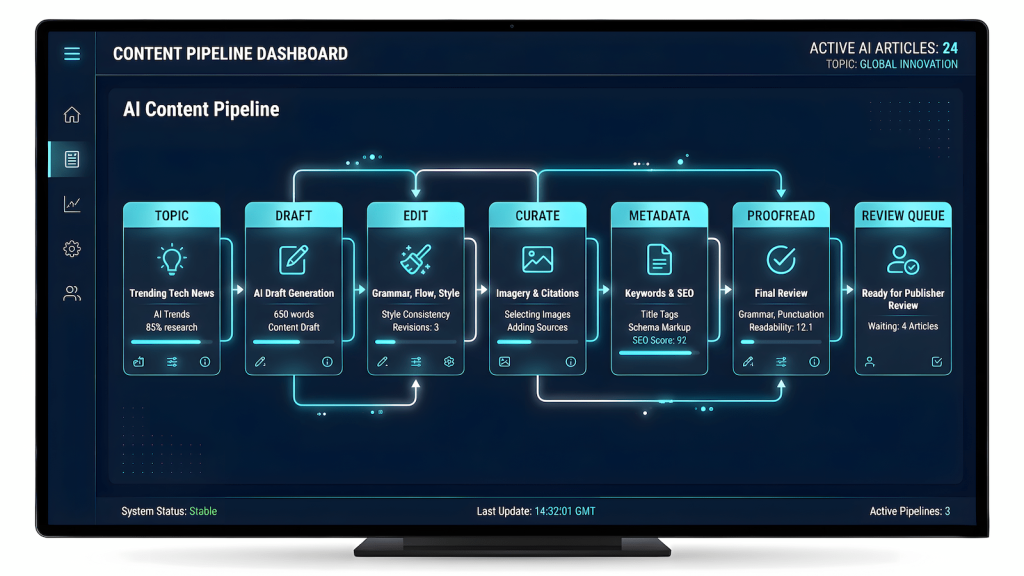
V3 restructured the pipeline from five stages to six and changed how publishing works entirely.
Topic generation
↓
Draft (Writer)
↓
Edit and challenge (Editor)
↓
Curation pass, AI enforces writing rules
↓
Metadata generation, only after curation passes
↓
Proofread, final pass
↓
Review Queue, sits here before publishing
↓
Approve, AutopostThe curation stage is the quality gate. It checks every draft against a specific set of rules before metadata is even generated. Paragraphs must have five or more sentences. No unnecessary dashes in body text. The search intent must be answered directly. The opening paragraph must be compelling. If the draft fails the curation check, the pipeline throws an error instead of posting garbage.
Metadata only generates after curation passes. That is how my real writing workflow works. I do not generate metadata until the draft is confirmed solid. The automation now follows the same logic.
The review queue is the human control point. Every draft lands in a queue before anything goes live. The dashboard shows the topic, site, niche, article type, and a preview of the SEO metadata. I can approve it immediately if it looks good, edit it inline if something needs fixing, or reject it entirely if it is not usable. The inline editor lets me change both the content HTML and every metadata field in the same screen before approving.
This is not a human rewriting the post. It is a human deciding whether the post ships. The same way a dev team lead reviews a pull request before it merges, not rewriting the code, just deciding if it is ready.
V3 also added sitemap URL support per site. The writer stage fetches existing posts from the sitemap and links to relevant ones naturally within each new article. Internal linking handled automatically, based on real published content.
The meta_keywords field that my functions.php uses to populate schema and keyword meta tags now gets populated correctly on every post, sourced from the semantic keywords the pipeline generates in Stage 1 and confirmed in Stage 5.
What the Experiment Is Actually Testing
The question is not whether AI can write a blog post. It can. The question is whether an AI writing team with no human in the loop for the actual content produces output that holds up the same way an AI development team produces code that ships.
Dev teams trust AI-generated code because there are tests, linters, and CI gates. Every stage has a quality check before the next stage runs. The curation stage, the proofread stage, the review queue, those are the equivalent. They are the tests that run before the content ships.
Four sites at one post per day for two weeks is fifty-six posts. That is enough data to answer whether the pipeline produces publishable content at scale, which article types perform, whether affiliate links convert, and whether Alfred and Edwin can carry a blog without a human writing anything.
That data does not exist yet. This post is the first entry in the experiment log.
The stack will change again. It always does.
AutoBlog AI is the tool. The experiment is what happens when you actually run it. Follow along at EngineeredAI.

Builds systems that should not exist, then documents what actually survived.
This article covers how a multi-model autonomous blogging engine got built in one conversation by someone who had never touched Python and why that is not the same as vibe coding.
Runs EngineeredAI.net, practical AI knowledge for people who need to understand which tools solve which problems, without the tech bro mysticism.
If it saves real time and works reliably across different workflows, it gets tested and explained in plain English.
